Algorithms, Design Methods, and Many-core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing
Artemis 2013 GA 621439
Project Description
Societal Impact
Objectives
Technical Innovation
Advanced image and video processing systems are becoming a crucial and resource consuming part of embedded applications in many sectors. ALMARVI aims to facilitate the transition from a vertically structured market to a horizontally structured market. In particular, it focuses on reducing overall system design cost and time-to-market and enabling low cost solutions for high volume markets in different industrial domains and creating new market opportunities, and supporting SMEs.
The demonstrators developed under this project for the healthcare, security/surveillance/monitoring, and mobile use cases will directly lead to marketable applications and products in their relevant domains. Integrated releases of the image/video processing algorithm libraries, reference design tools and platforms, and system software stack solutions will be made available along with their evaluation for the demonstrated use cases. Cross-domain applicability will reduce fragmentation, thus increasing the market share of European supplier industry.
Societal Impact
The project provides the core of solutions for the big societal challenges like affordable healthcare and wellbeing, green and safe transportation, and reduced consumption of power.
1. Enable cross-domain re-use and interoperability for different product categories and application domains, thus promoting cross-fertilization and reuse of technology results.
2. Facilitate predictable system and product properties, and robust solutions.
3. Develop joint hardware-software techniques for resource and power management, yet providing massive data-rate processing and supporting interoperability over cross-domain platforms.
Objectives
1. Reduce the cost of the system design 20% - 30% through modularity, flexible interfacing, adaptive architecture, execution platform with well-developed tool chains, adaptability and run-time configurability.
2. Reduce in development cycles 25% - up to 35% through seamless scalability and integration of hardware and software components and cross-domain component reuse, cross-domain system software stack, design tools, understanding of relevant system layers
3. Manage a complexity increase with 30% -60% effort reduction through novel algorithms, architecture, design tools, execution platforms, and system software stack with run-time adaptive resource and power management techniques
4. Reduce effort and time for re-validation and re-certification 15% - 20% through incremental design, develop, test, integrate, validate cycles.
5. Cross-sectoral re-usability of Embedded Systems 20% - 50% through system architecture accounting for the common requirements of different sectors and application domains.
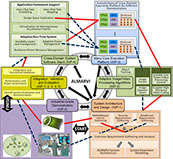
The key is to leverage the properties of image/video content while jointly adapting algorithms and hardware in order to achieve a much higher potential for power savings and to enable massive data rate processing. At the Application Layer, the goal is to adapt algorithms towards the architectures. At the System Software Stack Layer, the adaptive run-time system allocates resources to different applications executing simultaneously in an energy-efficient way. At the Hardware Layer, the ALMARVI’s many-core execution platform provides the compute capabilities to diverse image/video processing applications.



Work Packages
Overall Architecture
Work Packages
Work Packages
![]()
Start time: 01.04.2014 Duration: 36 Months Budget: EUR 8.789 M
Countries involved:
Netherlands Turkey Czech Republic Finland

About ALMARVI project
Consortium




.jpg)





News
ARTEMIS Conference
8-2016
IDEA 2016 Workshop
4-2016
Workshop in Istanbul
1-2016
ESWEEK Tutorial
10-2015
Workshop in Nokia
5-2015
TRACE New Version
5-2015
Workshop in Prague
2-2015
Global Conference
2-2015
Workshop in Kuopio
8-2014
ALMARVI Website
7-2014
Kick-Off Meeting
7-2014
Meeting in Brno
5-2016
ICPR tutorial session
12-2016
TUE Workshop
10-2016
TU Delft Workshop
2-2017
DIF 2017
3-2017
 ARTEMIS Technology Conference 2016
ARTEMIS Technology Conference 2016
ARTEMIS Industry Association organises the ARTEMIS Technology Conference (ATC), which will take place on 4-6 October 2016 in Madrid, Spain. More information of the conference are available here.
 IDEA 2016 workshop @ CPSWeek, April 2016
IDEA 2016 workshop @ CPSWeek, April 2016
A keynote from Zaid Al-Ars, of TU Delft, NL on the multi-core architecture
High Performance Embedded Computing Using Heterogeneous Computational Fabrics — The ALMARVI Vision and Beyond
In the past decade, demand for high performance computing has been steadily increasing throughout the computing spectrum, all the way from high-end supercomputers, down to small handheld devices. To facilitate this need in the field of embedded computing, various concepts have been proposed to bring high performance architectures to the embedded domain. However, the diverse and in many cases stringent application requirements in this domain (such as low power, portability, form-factor limitations, etc.) have made it difficult to come up with a single design paradigm that satisfies the wide variation of available applications. This results in the need to develop custom-made solutions for each application, with an associated high cost of design, debug and verification of the hardware and application software. In this talk, we discuss the current trends in high performance embedded systems, where heterogeneous computing plays an important role in satisfying the computational requirements of the system on the one hand, while software abstraction ensures easy programmability and portability of the developed application software. We also present the ALMARVI project vision and ongoing activities as an example of this trend. Finally, we show how this trend into heterogeneous computing is also penetrating the high performance computing field, resulting in the convergence of various aspects of the computational spectrum from the high-end to the embedded world.
 ALMARVI project workshop in Istanbul, Turkey
ALMARVI project workshop in Istanbul, Turkey
Özyegin University hosted a 2-day workshop on ALMARVI project beginning 14th Jan. 2016 in Istanbul, Turkey.
This meeting provided a great opportunity for EU partners to exchange ideas in order to develop Algorithms, Design Methods, and Many-Core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing. More photos of the workshop are available here.
 ESWEEK Tutorial in October, 2015
ESWEEK Tutorial in October, 2015
A half-day ESWEEK tutorial session on "Design Challenges in Compute-intensive Mixed-criticality Systems: System, Platform and Application Perspectives” will be presented jointly by ALMARVI and EMC2 partners on October 4th, 2015 in Amsterdam, Netherlands. More details can be found here.
 ALMARVI project workshop in Nokia, Finland
ALMARVI project workshop in Nokia, Finland
ALMARVI workshop hosted by Nokia at Nokia Training Center in Finland on May 12 and 13, 2015. That was the third workshop organized under ALMARVI for project-wide technical collaborations, and project management.
This meeting was a success providing a great opportunity for ALMARVI partners to exchange ideas in order to develop Algorithms, Design Methods, and Many-Core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing. More photos of the workshop are available here.
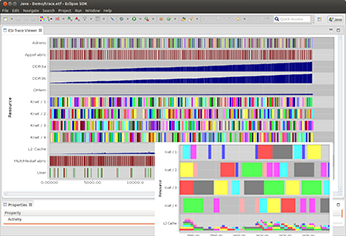 TRACE new version is released
TRACE new version is released
TNO-ESI, developer of the TRACE tool for Gantt chart visualization and analysis, has released a new version of the tool. The TU/e results developed in ALMARVI have been made available in TRACE.
TRACE is a Gantt chart visualization tool capable of presenting (large sets of) activities on resources (and dependencies between them) as a function of the time. Moreover, it allows visualizing multi-dimensional design spaces for easy comparison of design options. Key features include:
- Ability to configure identification, selection and visualization of such information to match your application domain
- Streaming input allowing 'live' visualization of Gantt charts
- Performance analysis (such as critical path, latency and throughput) based on Gantt chart data
- Comparison of traces for model validation and design-space exploration
- Visualization of design spaces covering a multitude of quantitative properties
- On-line user manual through Help menu
For more information about TRACE click here.
 ALMARVI project workshop in Prague, Czech Republic
ALMARVI project workshop in Prague, Czech Republic
Institute of Information Theory and Automation (UTIA) hosted a 2-day workshop on ALMARVI project beginning Feb. 3th, 2015 in Prague, Czech Republic.
This meeting provided a great opportunity for EU partners to exchange ideas in order to develop Algorithms, Design Methods, and Many-Core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing. More photos of the workshop are available here.
 IEEE Global Conference on Signal and information processing
IEEE Global Conference on Signal and information processing
IEEE Global Conference on Signal and Information Processing (GlobalSIP), a recently lunched flagship conference of the IEEE Signal Processing Society, will be held in Orlando, Florida, USA, December 14-16, 2015. More information
 ALMARVI project workshop in Kuopio, Finland
ALMARVI project workshop in Kuopio, Finland
School of Computing, University of Eastern Finland hosted a 2-day workshop on ALMARVI project beginning Sept. 9th, 2014 in Kuopio, Finland.
This meeting provided a great opportunity for EU partners to exchange ideas in order to develop Algorithms, Design Methods, and Many-Core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing.
 June 2014, ALMARVI web site launched
June 2014, ALMARVI web site launched
The ALMARVI website is launched! It provides information about the ongoing activities in ALMARVI to the consortium and the wider community.
 April 2014, ALMARVI kick-off meeting in Best, Netherlands
April 2014, ALMARVI kick-off meeting in Best, Netherlands
ALMARVI’s kick-off meeting was successfully held at Philips Healthcare in the presence of all project partners on April 15 and 16, 2014 in Best, the Netherlands. The meeting was a great occasion to get to know all consortium members and to exchange details about the program. Idea and background of the project were presented and discussed. Partners, who are responsible for the work packages, confirmed the content of their deliverables and their ideas on the first steps. There was an excellent motivating atmosphere among all partners and they were excited to get started with the project.
 ALMARVI project meeting in Brno, Czech Republic
ALMARVI project meeting in Brno, Czech Republic
Brno University of Technology hosted a 2-day meeting on ALMARVI project May 2016 in Brno, Czech Republic.
This meeting provided a great opportunity for EU partners to exchange ideas in order to develop the goals of the project. A number of demonstrations was given by the ALMARVI partners. More photos of the workshop are available here.
![]() ICPR Tutorial Session on "Handling Blur" 2016
ICPR Tutorial Session on "Handling Blur" 2016
A ICPR tutorial session on "Handling Blur” was presented on December 4th, 2016 at the 23rd International Conference on Pattern Recognition ICPR, Mexico by ALMARVI partner UTIA, Czech Republic. Two major approaches to handling blurred images was discussed – image restoration and blur-invariant approach. More details can be found here.
 ALMARVI project workshop in Eindhoven, Netherlands
ALMARVI project workshop in Eindhoven, Netherlands
Eindhoven University of Technology hosted a 2-day workshop on ALMARVI project beginning Oct. 2016 in Eindhoven, The Netherlands.
This meeting provided a great opportunity for EU partners to exchange ideas in order to develop Algorithms, Design Methods, and Many-Core Execution Platform for Low-Power Massive Data-Rate Video and Image Processing. More photos of the workshop are available here.
ALMARVI project workshop in Delft, Netherlands
Delft University of Technology hosted a 2-day workshop on ALMARVI project beginning Feb. 2017 in Delft, The Netherlands. This was the last regular workshop of ALMARVI project.
 ALMARVI project workshop in DIF 2017
ALMARVI project workshop in DIF 2017
ALMARVI project members participated in DIF conference May 2017, Amsterdam, Netherlands. More photos of the workshop are available here.
Open software
- SuRmob : The Institute of Information Theory and Automation (UTIA) introduced SuRmob which is an application for mobile devices (Andriod) for an acquisition of super-resolved images. Super-resolution is a mathematical algorithm that combines multiple low-resolution input images and creates one image of higher resolution. We provide an efficient implementation that runs in mobile devices equipped with digital cameras.
- vfTasks open-source parallelization library: Vector Fabrics (VF) maintains vfTasks which is a library with a C API containing the following features:
- Manage worker thread pools
- Inter-thread streaming communication channels
- 2-D synchronization for parallelized loops
It does not depend on any other libraries other than libc and the pthreads library. The latter can however be easily replaced with custom threading and memory allocation solution, allowing vfTasks to be ported to an embedded CPU or DSP processor. vfTasks is developed by VF and complements Vector Fabrics' Pareon product that helps to parallelize a C/C++ application. For more information, click here.
- TCE : TUT maintains TTA-based Co-Design Environment (TCE) which is a toolset for designing and programming customized processors based on the Transport Triggered Architecture (TTA). The toolset provides a complete retargetable co-design flow from high-level language programs down to synthesizable processor RTL (VHDL and Verilog backends supported) and parallel program binaries. Processor customization points include the register files, function units, supported operations, and the interconnection network.
- POCL : TUT uses Portable Computing Language (pocl) which aims to become a MIT-licensed open source implementation of the OpenCL standard which can be easily adapted for new targets and devices, both for homogeneous CPU and heterogenous GPUs/accelerators. IT uses Clang as an OpenCL C frontend and LLVM for the kernel compiler implementation, and as a portability layer. Thus, if your desired target has an LLVM backend, it should be able to get OpenCL support easily by using pocl. The goal is to accomplish improved performance portability using a kernel compiler that can generate multi-work-item work-group functions that exploit various types of parallel hardware resources: VLIW, superscalar, SIMD, SIMT, multicore, multithread.
- rVEX : TUDelft maintains ρ-VEX which is an reconfigurable and extensible Very-Long Instruction Word (VLIW) processor. It is part of the overall "Liquid Architectures" research theme within the Computer Engineering Lab at TU Delft, The Netherlands. The ρ-VEX processor architecture is based on the VEX ISA. The main concept of our design is to be able to dynamically adapt the hardware design to match requirements from the applications and the operating environment. In this manner, resource utilization can be improved for energy savings or increased performance, e.g., by executing additional programs on the "freed" resources. Consequently, our design can be seen as a large wide-issue (up to 8) VLIW processor or as several 2-issue VLIW cores. Our designs have been used also in several courses given at TU Delft and we can make this material available for professors at other institues upon request.
- SDF3 : TUE developed and maintains SDF3 toolchain. Synchronous dataflow (SDF) is a modelling formalism that allows design-time analysis of multiprocessor applications. SDF3 is the tool support for SDF based analysis of throughput and latency, and it provides solution to binding and scheduling questions on multiprocessors. The recent versions support Cyclo-Static Dataflow (CSDF) and Finite-State-Machine-based Scenario-Aware Dataflow (FSMSADF).
- TRACE : TRACE is a Gantt chart visualization tool capable of presenting (large sets of) activities on resources (and dependencies between them) as a function of the time. Moreover, it allows visualizing multi-dimensional design spaces for easy comparison of design options. Various recent features (e.g., critical path analysis, distance analysis etc.) on TRACE were developed as a part joint activities between TUE and TNO-ESI and are being used in ALMARVI project.
Publications
- A. Brandon, J. Hoozemans, J. Van Straten, S. Wong, “Exploring ILP and TLP on a Polymorphic VLIW Processor”, to appear in the proceedings of the 30th International Conference on Architecture of Computing Systems, Vienna, Austria, 2017.
- J. Hoozemans, R. Heij, J. Van Straten, S. Wong, “VLIW-based FPGA computational fabric with streaming memory hierarchy for medical imaging applications”, to appear in the proceedings of the 13th International Symposium on Applied Reconfigurable Computing, Delft, the Netherlands, 2017.
- F. Sroubek, J. Kamenicky, and Y. M. Lu, “Decomposition space-variant blur in image deconvolution”, in IEEE Signal Processing Letters, vol. 23, no. 3, pp. 346-350, 2016.
- E.P. van Horssen, A.R.B. Behrouzian, D. Goswami, D. Antunes, T. Basten and M. Heemels, “Performance analysis and controller improvement for linear systems with (m,k)-firm data losses”, in Proc. European Control Conference, ECC, Aalborg, Denmark, 2016.
- M. Buyukmihci, V.E. Levent, A.E. Guzel, O. Ates, M. Tosun, T. Akgun, C. Erbas, S. Gören, H.F. Ugurdag, "Output Domain Downscaler", in Proc. Intl. Symp. on Computer and Information Sciences (ISCIS), Krakow, Poland, 2016.
- A.E. Guzel, V.E. Levent, M. Tosun, M.A. Ozkan, T. Akgun, D. Buyukaydin, C. Erbas, H.F. Ugurdag, “Using High-Level Synthesis for Rapid Design of Video Processing Pipes”, in Proc. of East-West Design & Test Symposium (EWDTS), Yerevan, Armenia, 2016.
- M. Koskela, T. Viitanen, P. Jääskeläinen, and J. Takala, “Half-Precision Floating-Point Ray Traversal,” in Proc. Joint Conf. Comput. Vision Imaging Comput. Graphics Theory Appl., Rome, Italy, 2016.
- M. Hendriks, J. Verriet, T. Basten, B. Theelen, M. Brassé, and L. Somers, “Analyzing execution traces — critical-path analysis and distance analysis”, Accepted for publication in Springer International Journal on Software Tools for Technology Transfer, 2016.
- Šroubek Filip, Kamenický Jan, Lu Y. M. “Decomposition of Space-Variant Blur in Image Deconvolution” IEEE Signal Processing Letters vol.23, 3, pp. 346-350, 2016.
- Hadi Alizadeh Ara, Marc Geilen, Twan Basten, Amir Behrouzian, Martijn Hendriks and Dip Goswami, “Tight Temporal bounds for dataflow applications mapped onto shared resources”, Accepted for publication and presentation at the proceeding of the 11th IEEE International Symposium on Industrial Embedded Systems 23-25 May 2016.
- Amir Behrouzian, Dip Goswami, Marc Geilen, Martijn Hendriks, Hadi Alizadeh Ara, Eelco Horssen, Maurice Heemels and Twan Basten, “Sample-Drop Firmness Analysis of TDMA-Scheduled Control Applications”, Accepted for publication and presentation at the proceeding of the 11th IEEE International Symposium on Industrial Embedded Systems 23-25 May 2016.
- J. Kotera, B. Zitová and F. Šroubek, “PSF accuracy measure for evaluation of blur estimation algorithms”, Proc. of IEEE International Conference on Image Processing (ICIP), Quebec City, 2015.
- A. A. C. Brandon, J. J. Hoozemans, J. Van Straten, A. F Lorenzon, A. L. Sartor, A. C. S. Beck, S. Wong, “A Sparse VLIW Instruction Encoding Scheme Compatible with Generic Binaries” in Proc. International Conference on ReConFigurable Computing and FPGAs (ReConFig), Mayan Riviera, Mexico, 2015.
- J. J. Hoozemans, J. Johansen, J. Van Straten, A. A. C. Brandon, S. Wong, “Multiple Contexts in a Multi-ported VLIW Register File Implementation” in Proc. International Conference on ReConFigurable Computing and FPGAs (ReConFig), Mayan Riviera, Mexico, 2015.
- T. Äijö, P. Jääskeläinen, T. Elomaa, H. Kultala, and J. Takala, “Integer Linear Programming Based Scheduling for Transport Triggered Architecture,” ACM Trans. Architecture and Code Optimization, Vol. 12, Issue 4, pp. 59:1-59:22, 2015.
- P. Jääskeläinen, C.S. de La Lama, E. Schnetter, K. Raiskila, J. Takala and H. Berg: “pocl: A Performance-Portable OpenCL Implementation,” Int. J. Parallel Programming, Vol. 43, Issue 5, pp. 752 – 785, 2015.
- H. Yviquel, A. Sanchez, P. Jääskeläinen, J. Takala, and M. Raulet, “Embedded Multi-Core Systems Dedicated to Dynamic Dataflow Programs,” J. Signal Processing Systems, Vol. 80, Issue 1, pp. 121 – 136, 2015.
- P. Jääskeläinen, H. Kultala, T. Viitanen, and J. Takala, “Code Density and Energy Efficiency of Exposed Datapath Architectures,” J. Signal Processing Systems, Vol. 80, Issue 1, pp. 49-64, 2015, doi:
- V. Korhonen, P. Jääskeläinen, M. Koskela, T. Viitanen, and J. Takala, “Rapid Customization of Image Processors Using Halide,” in Proc. IEEE Global Conf. Signal Inf. Process., Orlando, FL, USA, 2015.
- J. Glossner, P. Blinzer, and J. Takala, “HSA-Enabled DSPs and Accelerators,” in Proc. IEEE Global Conf. Signal Inf. Process., Orlando, FL, USA, 2015.
- T. Viitanen, M. Koskela, P. Jääskeläinen, H. Kultala, and J. Takala, “MergeTree: A HLBVH Constructor for Mobile Systems,” in ACM SIGGRAPH Asia, Kobe, Japan, 2015.
- H. Kultala, J. Multanen, P. Jääskeläinen, and J. Takala, “Impact of Operand Sharing to the Processor Energy Efficiency,” in Proc. CSI Int. Symp. Comput. Arch. & Digital Syst., Tehran, Iran, 2015.
- M. Koskela, T. Viitanen, P. Jääskeläinen, J. Takala, and K. Cameron, “Using Half Floating-Point Numbers for Storing Bounding Volume Hierarchies,” in Computer Graphics International Conference, Strasbourg, France, 2015.
- J. Kotera, F. Sroubek and B. Zitova, "PSF accuracy measure for evaluation of blur estimation algorithms", in International Conference on Image Processing (ICIP), Canada, 2015, (accepted for publication)
- I. Szentandrási, M. Zachariáš, J. Tinka, M. Dubská, J. Sochor and A. Herout, “INCAST”, in International Symposium on Mixed and Augmented Reality (ISMAR), Fukuoka, Japan, 2015
- M. J. Turnquist, M. Hiienkari, J. Makipaa and L. Koskinen, “A Fully Integrated Self-Oscillating Switched-Capacitor DC-DC Converter for Near-Threshold Loads” in Asian Solid-State Circuits Conference (A-SSCC), 2015 (accepted for publication)
- M. Hradiš, J. Kotera, P. Zemčík and F. Šroubek, “Convolutional Neural Networks for Direct Text Deblurring”, in Proceedings of The British Machine Vision Association and Society for Pattern Recognition BMVC, Swansea, UK, 2015
- B. Braithwaite, H. Niska, I. Pöllänen, T. Ikonen, K. Haataja, P. Toivanen, and T. Tolonen, “Optimized Curve Design for Image Analysis Using Localized Geodesic Distance Transformations”, In IS&T SPIE Electronic Imaging, California, USA, 2015
- A. R. B. Behrouzian, D. Goswami, T. Basten, M. Geilen and H. Alizadeh Ara, “Multi-Constraint Multi-Processor Resource Allocation”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- D. Buyukaydin and T. Akgun, “GPU Implementation of an Anisotropic Huber-L1 Dense Optical Flow Algorithm Using OpenCL”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- J. Multanen, T. Viitanen, H. Linjamäki, H. Kultala, P. Jääskeläinen, J. Takala, L. Koskinen, J. Simonsson, H. Berg, K. Raiskila and T. Zetterman, “Power Optimizations for Transport Triggered SIMD Processors”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- J. Hannuksela, M. Niskanen and M. Turtinen, “Performance evaluation of image noise reduction computing on a mobile platform”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- J. Kadlec, “Video Chain Demonstrator on Xilinx Kintex7 FPGA with EdkDSP Floating Point Accelerators”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- I. Pöllänen, B. Braithwaite, K. Haataja, T. Ikonen and P. Toivanen, “Current Analysis Approaches and Performance Needs for Whole Slide Image Processing in Breast Cancer Diagnostics”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- J. Hoozemans, S. Wong and Z. Al-Ars, “Using VLIW Softcore Processors for Image Processing Applications”, in International conference on Embedded Computer Systems: Architecture, Modeling, and Simulation (SAMOS), Samos, Greece, 2015.
- T. Viitanen, H. Kultala, P. Jääskeläinen and J. Takala,"Heuristics for greedy transport triggered architecture interconnect exploration", in International Conference on Compilers, Architecture and Synthesis for Embedded Systems (CASES), India, 2014
- I. Pöllänen, B. Braithwaite, T. Ikonen, H. Niska, K. Haataja, P. Toivanen, and T. Tolonen, “Computer-Aided Breast Cancer Histopathological Diagnosis – Comparative Analysis of three DTOCS-based Features: SWDTOCS, SW-WDTOCS, and SW-3-4-DTOCS”, In 4th International Conference on Image Processing Theory, Tools, and Applications (IPTA), France, 2014
- H. Kultala, T. Viitanen, P. Jääskeläinen, J. Helkala, J. Takala, "Compiler optimizations for code density of variable length instructions", In IEEE Workshop on Signal Processing Systems (SiPS), Ireland, 2014
- T. Ikonen, H. Niska, B. Braithwaite, I. Pöllänen, K. Haataja, P. Toivanen, J. Isola, and T. Tolonen, “Computer-Assisted Image Analysis of Histopathological Breast Cancer Images Using Step-DTOCS”, In 14th International Conference on Hybrid Intelligent Systems (HIS), Kuwait, 2014
- D. Goswami, D. Müller-Gritschneder, T. Basten, U. Schlichtmann and S. Chakraborty, “Fault-tolerant Embedded Control Systems for Unreliable Hardware,” In International Symposium on Integrated Circuits (ISIC), Singapore, 2014
- I. Zliobaite, J. Hollmén, J. Teittinen and L. Koskinen, “Towards hardware-driven design of low-energy algorithms for data analysis” in ACM SIGMOD Record archive, 2014
- K. van Gend, “Cut Power Consumption by 5x Without Losing Performance”, in LinuxCon, Düsseldorf, Germany, 2014
Technical Reports
- Article in the ARTEMIS-IA news, March 17, 2015
- Full HD HDMI In-Out HW-Accelerated Demos for Zynq System-on-Module TE0720-03-2IF and TE0701-05 Carrier Board
- ALMARVI Python Camera Platform
- Toshiba Video Sensor Evaluation Platform for TE0720-03-2IF SoM on TE0701-05 Carrier
- Python 1300 Video Sensor Evaluation Platform for TE0720-03-2IF SoM on TE0701-05 Carrier
Public Deliverables
Download D 1.3
Cross-Layer Models for estimating System Properties/Parameters
Download D 2.4
Parallel and Power-Aware Image Segmentation Algorithms (Architecture and Design)
Download D 2.5
Parallel Object Recognition and Tracking, Motion Analysis Algorithms (Architecture and Design)
Download D 2.7
Parallel Image Enhancement, Restoration, and Fusion Algorithms (Architecture and Design)
Download D 3.3
Abstracting heterogeneous hardware architectures
Download D 3.5
Scalability, quality and usability of the execution platform
Download D 4.3
Design Space Exploration
Download D 4.6
Integrated System Software Stack
Download D 5.7
Evaluation of the ALMARVI Demonstrators
Download D 6.4
Progress Efficiency Report-1
Download D 6.5
Progress Efficiency Report-2
Download D 6.9
Project final report
Download D 7.1
ALMARVI Project Website
Download D 7.3
ALMARVI Dissemination plan and strategies
Download D 7.6
Dissemination Report (Intermediate)
Download D 7.7
Dissemination Report (Final)
Download D 7.9
Standardisation Efforts
Contact us

Project Manager
Technical Manager
Dissemination Manager
Web-Master
2014 ALMARVI. All Rights Reserved